
A Tiny Cartography of Mapping Literature
My guess is that almost any reader will recognize the map from figure 1, just below. It is a map of Middle Earth. This image was reproduced from the 1993 paperback edition of J.R.R. Tolkien’s The Lord of the Rings. The map and its various siblings that have adorned some of the first pages of virtually every edition are pretty much emblematic for the archetypal use of maps in fiction, which seems to be to provide some cartography for the story world of the novel. Maps are typically embedded as front or back matter, but sometimes they are even independent companions to the primary work (fig. 2). Maps as paratext may relate to the real world, to imaginary geographies, and really anything in between.
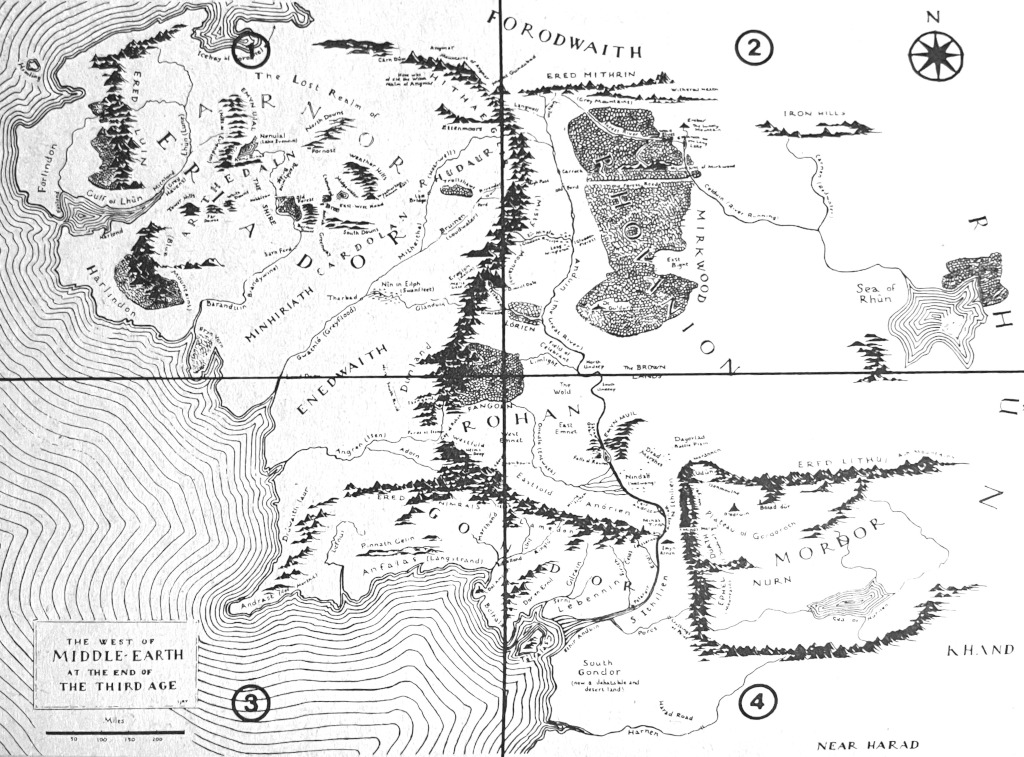 Fig. 1: Map of a fictional world.
Fig. 1: Map of a fictional world.
 Fig. 2: The map of the Disc World.
Fig. 2: The map of the Disc World.
Maps have played such a prominent role in literature that they now even need to be mapped out themselves, leading to interesting exhibitions for instance. Apparently readers (or at least some readers) are fascinated by the geography of novel space. But their fascination is not limited to maps pictured in novels. Readers want to know where authors lived (fig. 3). They love “book lovers’ tours”, such as the one in Amsterdam (fig. 4), where many stories were situated. But there are plenty of walks outside of Amsterdam as well. In fact, so many that they warrant a very own website (fig. 5) and app – although sadly, that last one seems out of service currently.
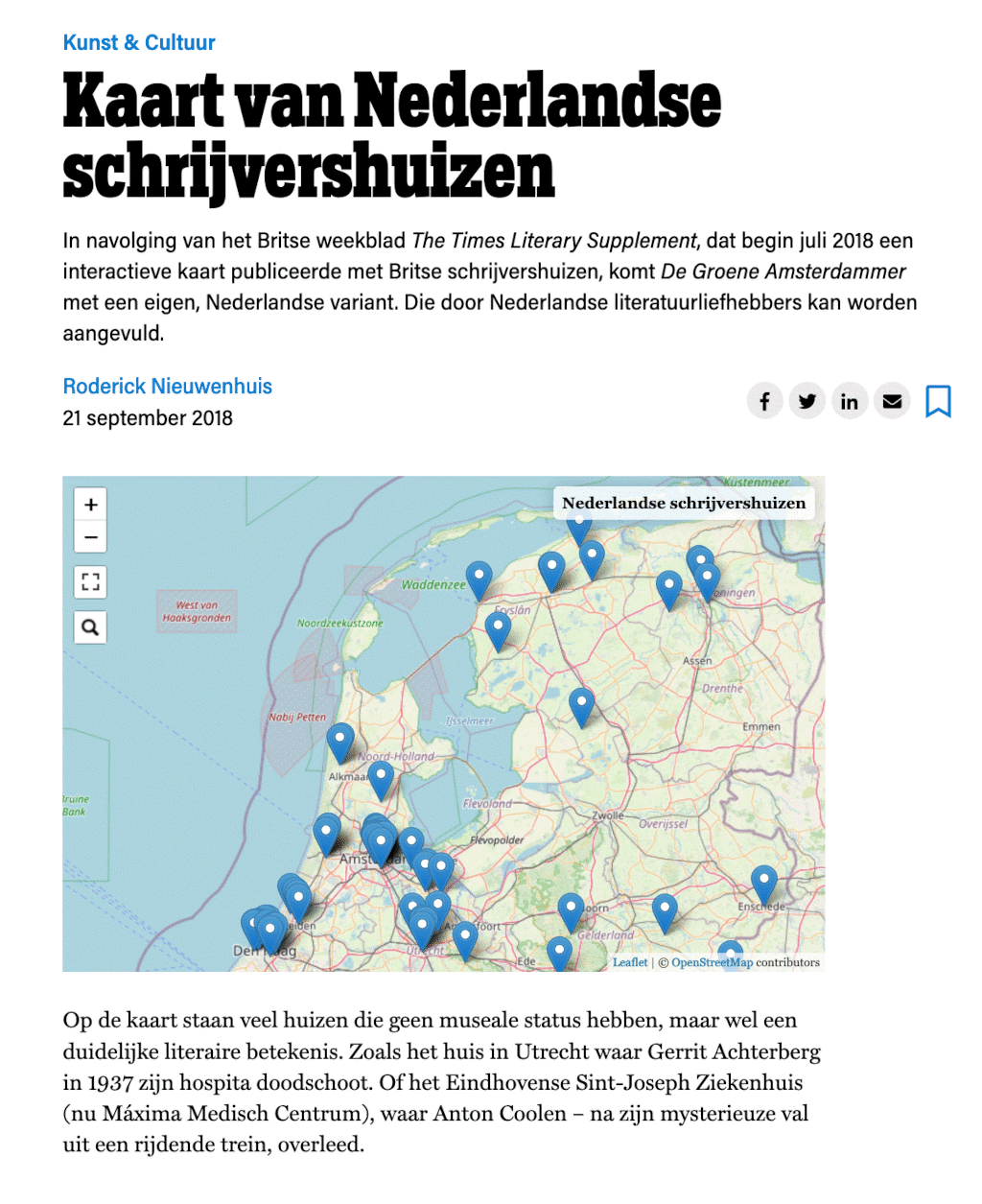 Fig. 3: Map of homes of Dutch literary authors.
Fig. 3: Map of homes of Dutch literary authors.
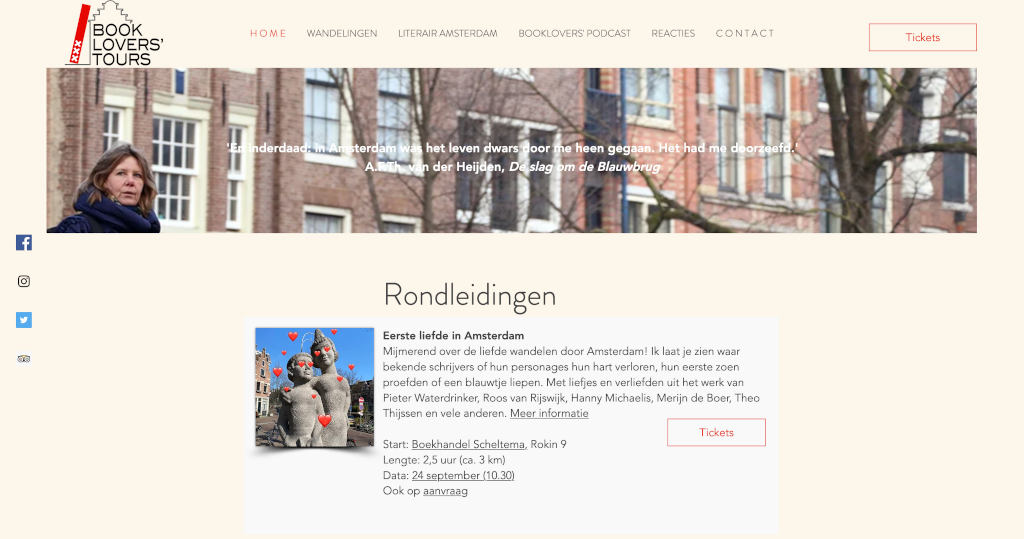 Fig. 4: Amsterdam’s Book Lovers’ Tour.
Fig. 4: Amsterdam’s Book Lovers’ Tour.
 Fig. 5: Many more literary walks exist.
Fig. 5: Many more literary walks exist.
Others have creatively tried to map literary quotes or titles of novels. There is a map of Amsterdam made up of literary quotes for instance (fig. 6). And there is a map of the whole of world literature (fig. 7) – obviously biassed and painfully selective as such a project must be.
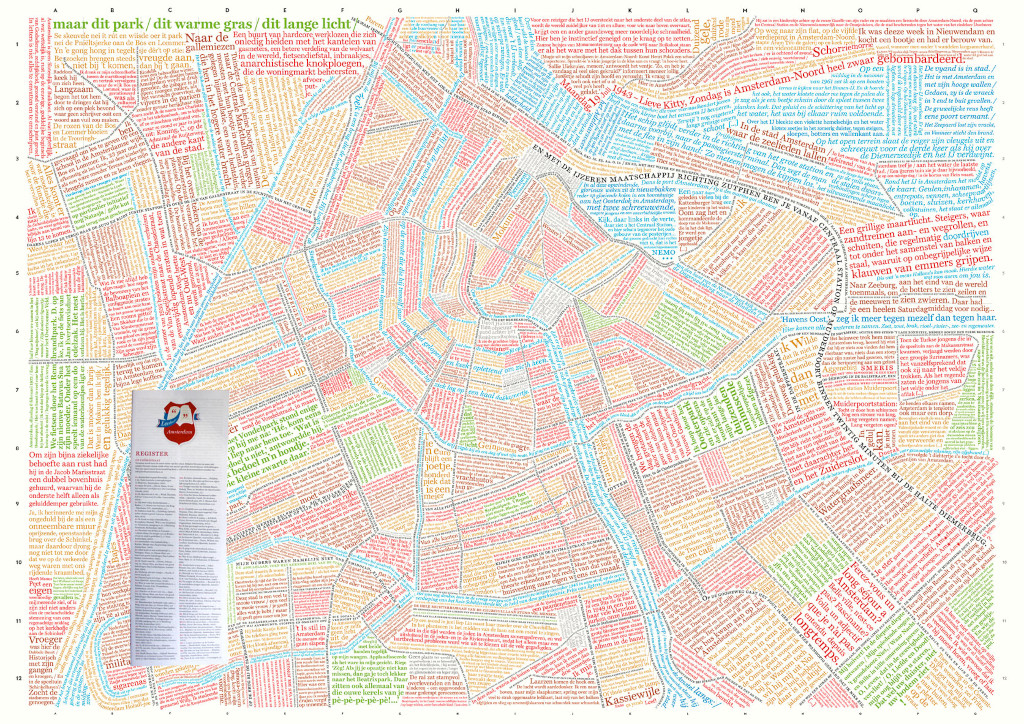 Fig. 6: Amsterdam in literary quotes.
Fig. 6: Amsterdam in literary quotes.
 Fig. 7: Martin Vargic, a map of world literature.
Fig. 7: Martin Vargic, a map of world literature.
Notwithstanding that there clearly is a relation of interest between literary texts and space –be it narrative space or geographical space– the cartography of Dutch literature as a scientific practice seems to be at most in a nascent state. This may be related to the question what exactly should be or can be mapped. Certainly in literature all things are in principle fictional. Although any story may point to some reality that exists externally to it, we can never be sure about what we get told about that reality. How truthful or deceitful are the connections and relations between narrative and reality that the story wants us to believe that exist? It is of course exactly their fictionality that allows texts themselves to be maps that help us navigate the world we live in. Texts and narratives help us to understand and grapple with people, events, history, and society. They are traveling guides. But, as we know well, “the map is not the territory” (Korzybsk 1958[1933]). And therefore: how useful is it to paint a map of a story world? It might just suggest too much relevance of real world geography and physics for the narrative space, for at least in stories time travel is possible and roads need not to lead from A to B. The essence of the story space is probably exactly in how it deviates from the reality we perceive.
But narrative philosophy aside, there are also more practical matters. How does one map narrative space, or for that matter, literature? Cartography is a much more practiced exercise in linguistics. I am reminded of Margit Rem’s painstaking cartography of the language differences in the written diplomatic legacy of the court of Holland (fig. 8). Rem worked at the Meertens Institute, which itself derives part of its fame from its long standing history of making maps of language, language change, and dialects, and so forth. Traditionally these were visual maps only, but by courtesy of new media also speaking maps now exist.
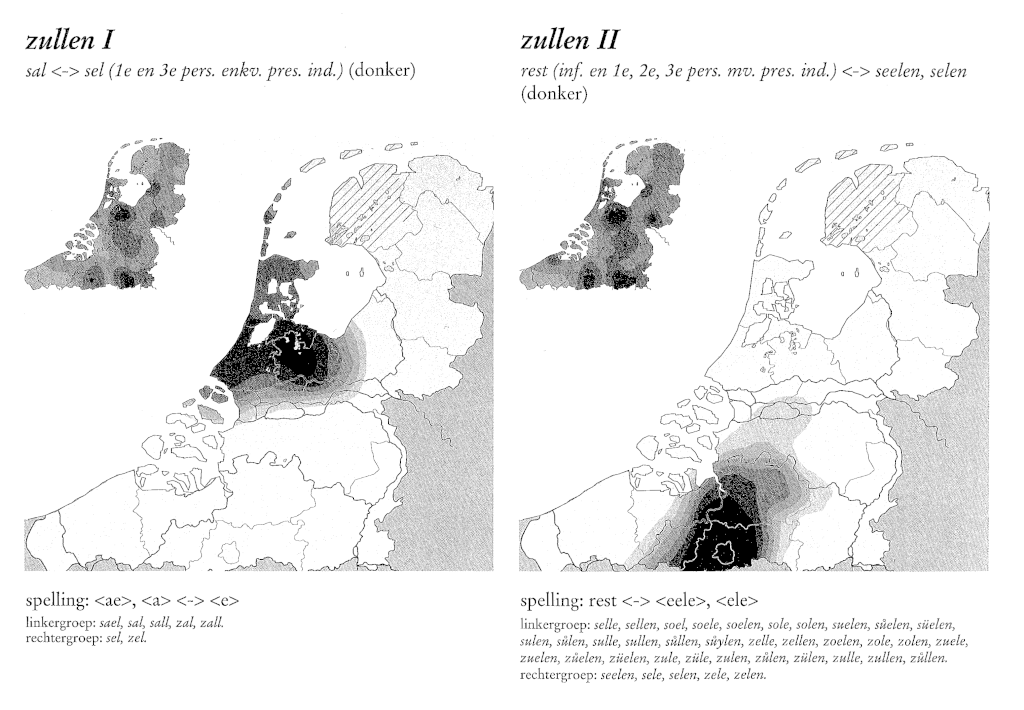 Fig. 8: An example of mapping the language of clerks working at the court of Holland in late medieval times. Reproduced from Rem 2003.
Fig. 8: An example of mapping the language of clerks working at the court of Holland in late medieval times. Reproduced from Rem 2003.
However, because language is strongly geographically linked, the role of cartography in linguistics is more or less obvious. In literary research that role is far less obvious and the relation between text and fictional geography is –often intentionally– complicated. Consequently, I think, we find few attempts so far to “map” Dutch literature. Herman Lodewick –famous for two text book anthologies that introduced several generations of secondary school pupils and students to the landscape of Dutch literature– published an “atlas” of Dutch literature together with two co-authors (fig. 9). In reality it was not so much a set of maps as it was “just another” anthology. Mapping Dutch literature has mostly meant describing a literary history, with sometimes a little attention to the relation between that literature and the geographical world or world view it functioned within. The Digital Library of Dutch Literature (DBNL) seems to have gotten the farthest with an actual attempt at mapping Dutch literature, providing a clickable map that ties author names to geographical locations.
 Fig. 9: Lodewick’s “Atlas” of Dutch Literature.
Fig. 9: Lodewick’s “Atlas” of Dutch Literature.
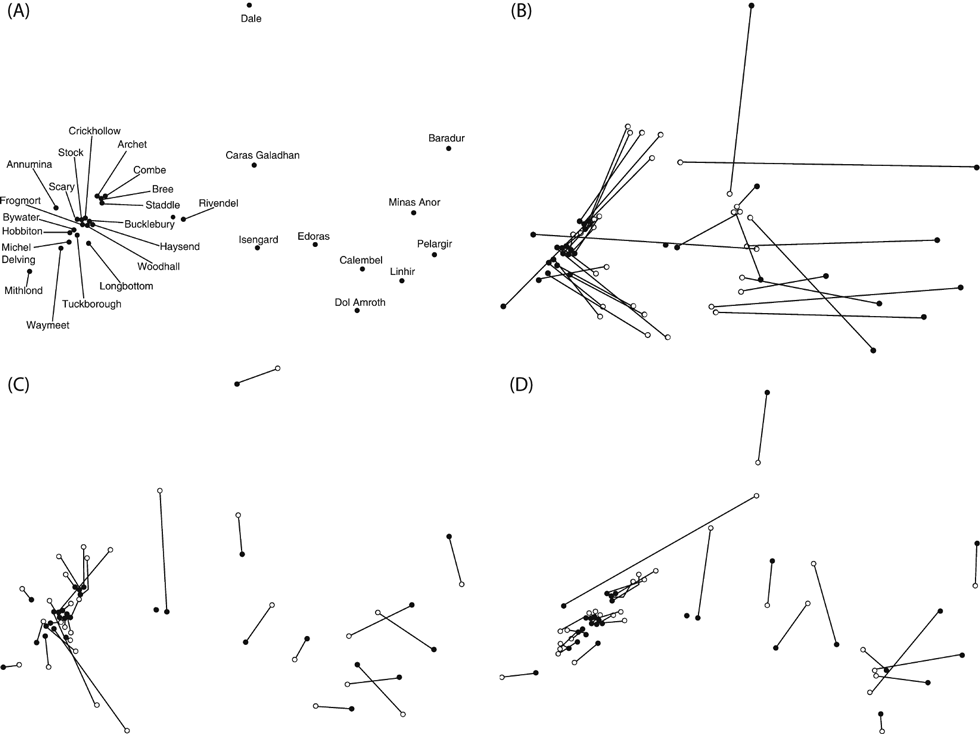
With more and more literature becoming available as digital data, and with developing computational techniques and skill, this nascent state may be changing a little. One example of trying to computationally map a narrative world we find in Louwerse and Benesh 2012. The authors are interested in how spatial mental representations can be gauged from language, veering close towards the computation of fictional world maps, resulting in fascinating calculated maps (fig. 10).
Mapping literature at large remains a desideratum. In the Impact and Fiction project we are most certainly not aiming to change or even add to the ground-works of digital literature cartography. However, while investigating the texts and metadata of our corpus of 19,622 works of fiction and non-fiction, we may serendipitously be producing some possibly interesting maps of Dutch literature, or part thereof. We are trying to make sense of what kind of works of fiction cause which kind of impact in what type of reader. To do this we need to be able to relate the vocabulary of the novels to impact described by readers in online reviews. In practice this means trying to reduce the countless linguistic and semantic features of the texts to a few that we hypothesize may relate to such reader impact. One notion of such features are the words that relate to topic, theme, or genre. Neither of those three concepts, however, has been unambiguously formalized and computationally operationalized. Nobody seems to know exactly what theme is, what topic looks like, and what a genre’s vocabulary is. These things are vague, and shifty, and hard to compute.
Nevertheless we try, and one attempt we did was in topic modeling the whole corpus. Topic modeling tries to identify which words occur often together in texts, and subsequently clusters texts based on those shared occurrences. Effectively it “maps” texts to certain points in a very high dimensional space, and texts that use common word pairs often all end up somewhere close to the same point in that space. Unfortunately the 600,000 or so dimensional world is not easy for us to navigate as lower dimensional beings. We need techniques –in our case called UMAP– to project that territory on to a two dimensional surface, just as cartographers do with three dimensional territories.
In the case of our corpus we end up with something that we could call a map of 19,000+ (fig. 11) novels. The colored clusters you see are clusters of topics and we were able to establish that these topics correlated very narrowly with genre. But another observation is that the clusters are also very much related to authors; see figure 12, where colors represent (a few) authors rather than topics. Does that mean that topics are both indicative for author and genre? Well, yes and no. Yes, because intuitively we can understand that many topics relate to specific genres (e.g. physical violence will be present more in war novels and murder mysteries, while less so maybe in a literary novellas). Also intuitively we can see how many authors will stay well within one (or a few) genres. But no, the other possibility that we need to delve into is that the selection of features we use and the techniques we apply are not sensitive enough to paint a decent map of the territory.
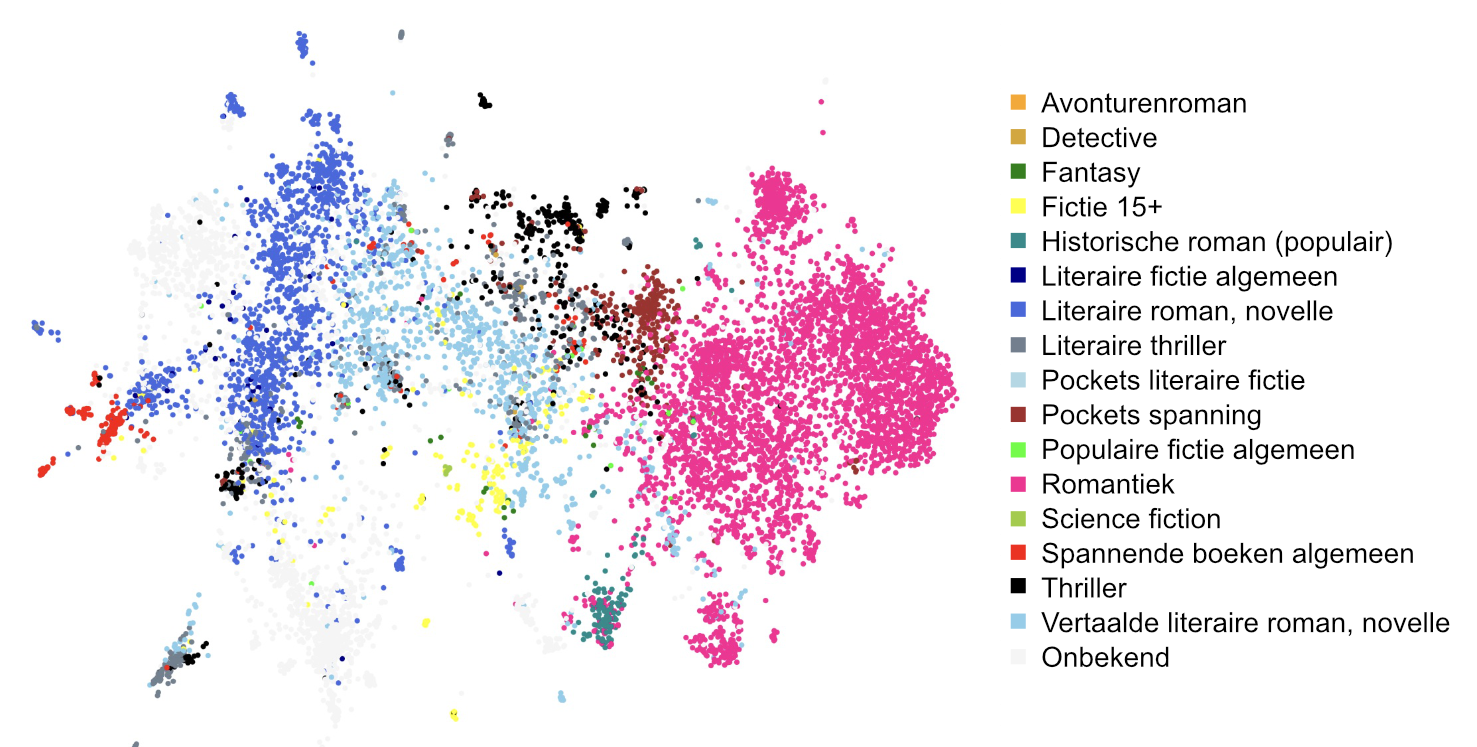 Fig. 11: UMAP 2D projection of a high dimensional topic space, clearly showing how genres (colors) cluster.
Fig. 11: UMAP 2D projection of a high dimensional topic space, clearly showing how genres (colors) cluster.
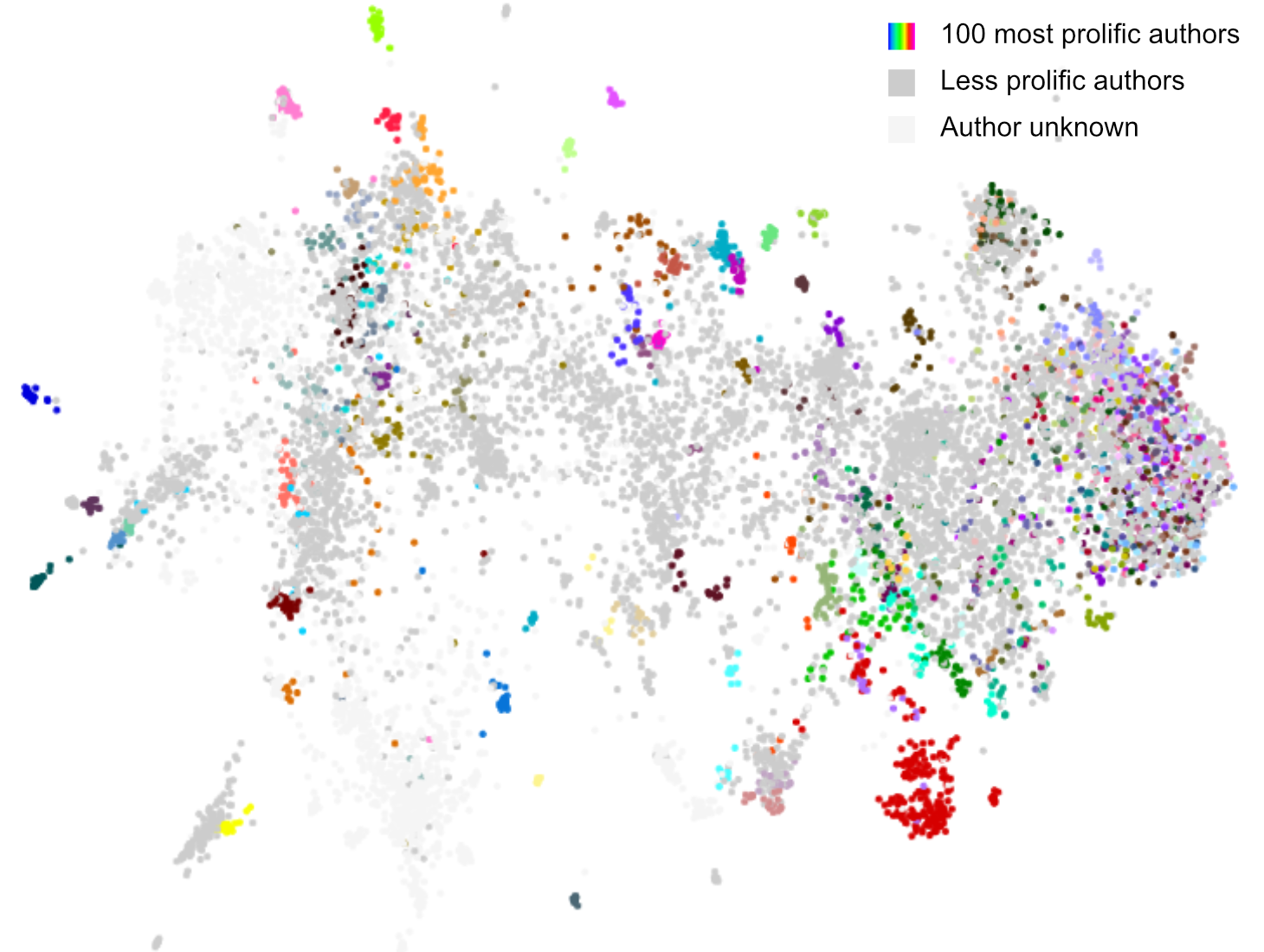 Fig. 12: The same, but now colors have been used to indicated the most prolific authors.
Fig. 12: The same, but now colors have been used to indicated the most prolific authors.
Mapping Dutch literature using topic models results in a map that tells us how topics are distributed over genres and authors. But we learned from this that our cartographic tools are crude to say the least. We need better digital theodolites and a more sophisticated computational literary GPS. That is part of the work ongoing in our project. Of course there is no reason why we would not meanwhile enjoy the maps we already made.
Note
This blogpost is a copy of the one I wrote for the blog of Impact & Fiction in december 2022.
References
- Louwerse, Max M., and Nick Benesh. 2012. “Representing Spatial Structure Through Maps and Language: Lord of the Rings Encodes the Spatial Structure of Middle Earth.” Cognitive Science 36 (8): 1556–69. https://doi.org/10.1111/cogs.12000
- Korzybski, Alfred. 1958. Science and Sanity: An Introduction to Non-Aristotelian Systems and General Semantics. 5th (first published 1933). New York: International Non-Aristotelian / Institute of General Semantics.
- M. Rem, De Taal van de Klerken Uit de Hollandse Grafelijke Kanselarij (1300-1340). 2003. Naar Een Lokaliseringsprocedure Voor Het Veertiende-Eeuws Middelnederlands. Amsterdam: Stichting Neerlandistiek VU.


